
OpenAI Releases GPT-5.2: The First AI That Outperforms Industry Professionals
OpenAI just dropped GPT-5.2 and the benchmarks are absolutely wild. This isn't just another incremental update. For the first time ever, an AI model consistently beats human industry professionals at real-world knowledge work.
The Benchmarks Speak for Themselves
| Benchmark | GPT-5.2 Thinking | GPT-5.1 Thinking |
|---|---|---|
| GDPval (Knowledge work) | 70.9% | 38.8% |
| SWE-Bench Pro (Software engineering) | 55.6% | 50.8% |
| SWE-Bench Verified (Software engineering) | 80.0% | 76.3% |
| GPQA Diamond (Science questions) | 92.4% | 88.1% |
| CharXiv Reasoning (Scientific figures) | 88.7% | 80.3% |
| AIME 2025 (Competition math) | 100.0% | 94.0% |
| FrontierMath Tier 1-3 (Advanced math) | 40.3% | 31.0% |
| FrontierMath Tier 4 (Advanced math) | 14.6% | 12.5% |
| ARC-AGI-1 (Abstract reasoning) | 86.2% | 72.8% |
| ARC-AGI-2 (Abstract reasoning) | 52.9% | 17.6% |
Look at that ARC-AGI-2 jump. From 17.6% to 52.9%. That's a 3x improvement in genuine abstract reasoning ability in one generation.
The Number That Matters Most
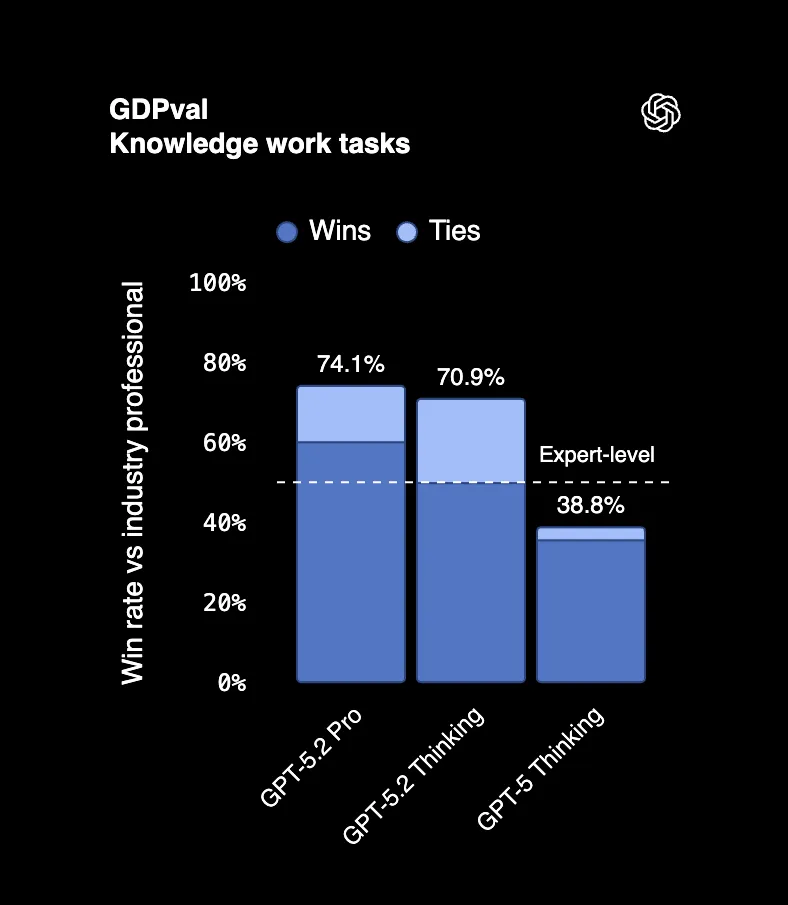
On GDPval, a benchmark measuring actual professional tasks across 44 occupations, GPT-5.2 Thinking beats or ties top industry professionals 70.9% of the time. We're talking about creating presentations, building spreadsheets, writing reports, the stuff people get paid six figures to do.
One judge reviewing the outputs said it "appears to have been done by a professional company with staff." That's not a typo. An AI output being mistaken for work from an entire team.
And here's the kicker: GPT-5.2 produced these outputs at 11x the speed and less than 1% of the cost of expert professionals.
100% on Competition Math
GPT-5.2 Thinking scored 100% on AIME 2025, a prestigious math competition that stumps most humans. Not 99%. Not 98%. Perfect score.
On FrontierMath, which tests expert-level mathematics that even PhD mathematicians struggle with, it hit 40.3%, up from 31% with GPT-5.1.
Coding Just Got Serious
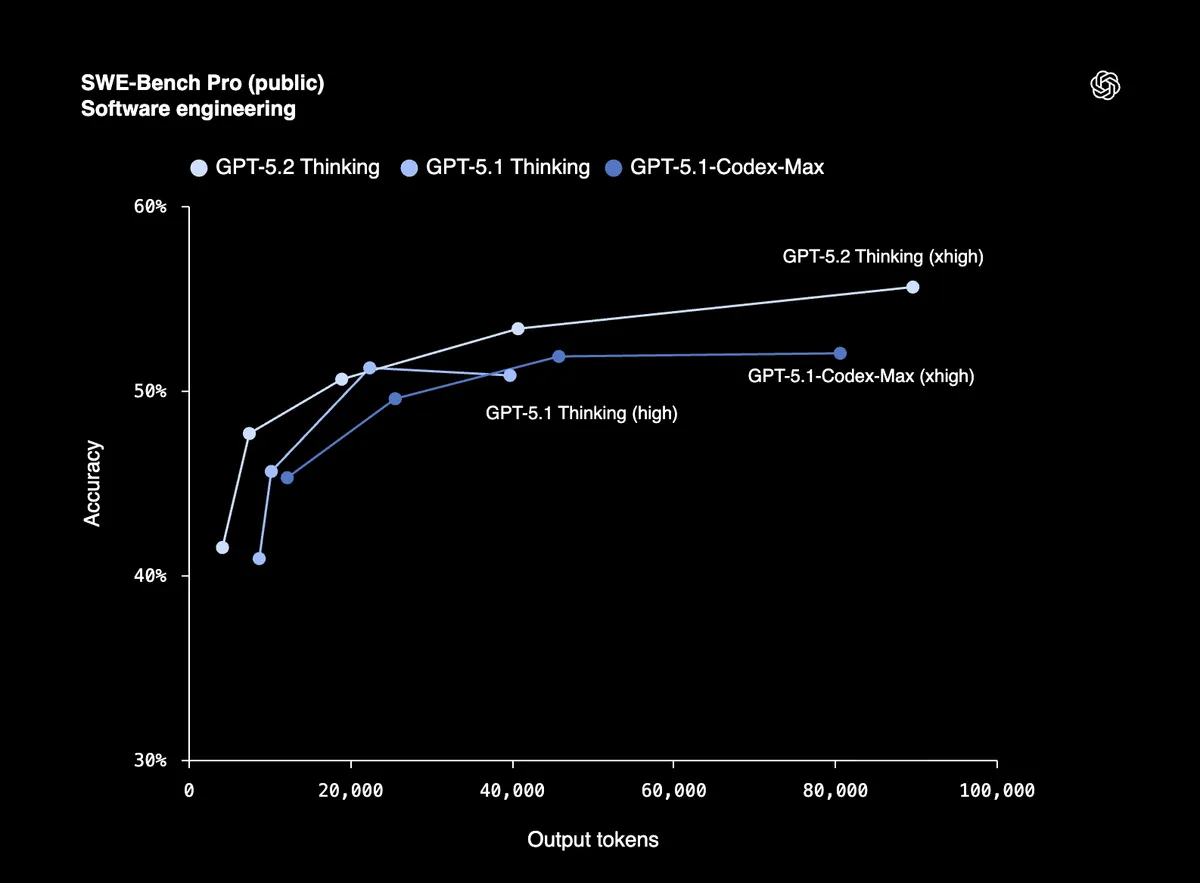
An 80% score on SWE-Bench Verified means GPT-5.2 can reliably debug production code, implement features, and refactor large codebases with minimal hand-holding. SWE-Bench Pro tests real-world software engineering across four programming languages, not just Python.
Early testers from Windsurf, JetBrains, and Warp are calling it "the biggest leap for GPT models in agentic coding since GPT-5."
30% Fewer Hallucinations
This one matters for anyone using AI professionally. GPT-5.2 Thinking produces 30% fewer responses with errors compared to GPT-5.1. For research, analysis, and decision-making, that's a massive reliability boost.
The Long Context Breakthrough
GPT-5.2 is the first model to achieve near 100% accuracy on long-context tasks up to 256k tokens. That means you can feed it entire codebases, contracts, research papers, or transcripts, and it actually maintains coherence across all of it.
Previous models would lose the plot halfway through. GPT-5.2 doesn't.
Vision That Actually Works
Error rates on chart reasoning and software interface understanding were cut roughly in half. The model can now accurately interpret dashboards, technical diagrams, and screenshots, making it genuinely useful for visual analysis tasks.

What This Means for You
If you're already paying for ChatGPT Plus or Pro, GPT-5.2 is rolling out now. API pricing is $1.75 per million input tokens and $14 per million output tokens, with a 90% discount on cached inputs.
The average ChatGPT Enterprise user already reports saving 40-60 minutes daily. Heavy users claim over 10 hours per week. With GPT-5.2, those numbers are only going up.
The Bottom Line
GPT-5.2 isn't just better. It's crossing thresholds we thought were years away. Perfect scores on math competitions. Beating professionals at their own jobs. Near-perfect long-context understanding.
We're watching the gap between AI assistance and AI capability close in real time.
